
Databricks Auto Loader use case
Databricks Auto Loader is a feature that allows us to quickly ingest data from Azure Storage Account, AWS S3, or GCP storage. It uses Structured Streaming and checkpoints to process files when files appear in a defined directory. You can use Auto Loader to process billions of files to populate tables. It also supports near real-time ingestion or can be executed in batch mode.
Databricks Auto Loader use case
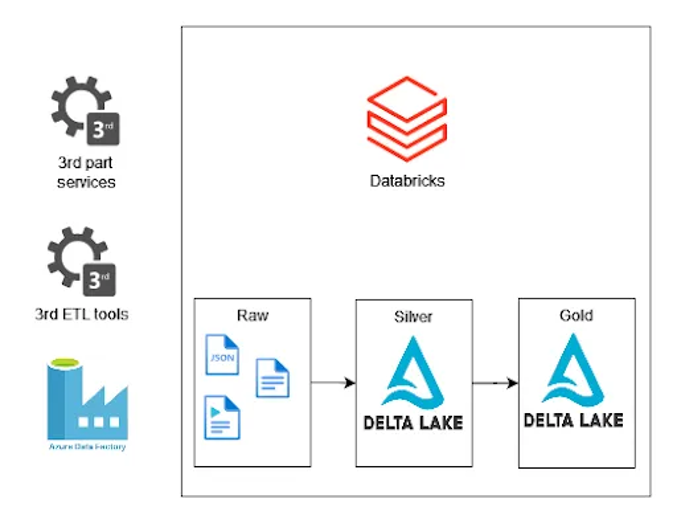
When we ingest data from external sources, we can use cloud native tools like Oracle, SQL Server, Db2, PostgreSQL, SAP, Salesforce, etc. To extract data from sources and store it in the Data Lake, we can use tools like Informatica, SSIS, custom scripts, services, or applications. The problem that we face is detecting new files and process orchestration. Databricks Auto Loader solves this problem because it detects new files and keeps information about processed files in the checkpoint locations in the RockDb database. Moreover, it uses Structured Streaming, so we could build a near real-time process to populate our tables.
Implementation of Databricks Auto Loader in Azure
To make our PySpark script executable, we need to configure a Service Principal, or we can use the SAS key and the access key from the storage account. One of the good practices is to store information in Azure KeyVault and configure the Secrete Scope in Databricks to use it in a code.
Code implementation
When we use cloudFiles.useNotifications property, we need to give all the information that I presented below to allow Databricks to create Event Subscription and Queue tables.