
Why Are Data Pipelines Needed?
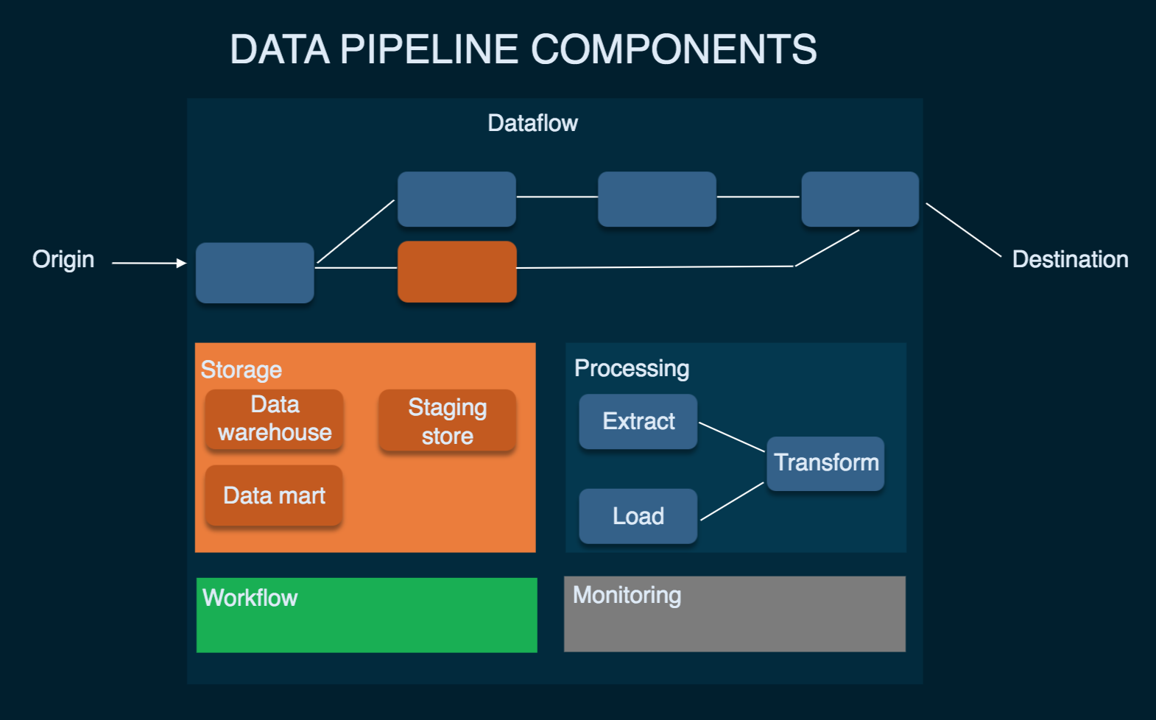
Understanding Data Pipelines
A data pipeline is a series of processes that collect, transform, and move data from one or more sources to a destination where it can be stored, analyzed, and utilized. Data pipelines play a crucial role in modern data-driven organizations by facilitating the efficient and automated flow of data.
What is a Data Pipeline?
- A data pipeline collects data from multiple sources, processes it if required, and transfers it to a destination repository.
- It involves a series of steps, starting with identifying relevant data sources, aggregating the dispersed data, performing necessary data processing measures such as filtering, transformation, and validation, and finally, loading it into data warehouses.
- Data pipeline got its name because it acts as a "pipeline" for the flow of data from source to destination.
- A data pipeline automates the process of centralizing scattered and fragmented data.
- It improves data quality by converting raw data into an organized format from which actionable insights can be derived.
Why Are Data Pipelines Needed?
Automates data consolidation
Despite the availability of SaaS apps with open APIs, data remains isolated in disparate databases. Consolidate your data sources into a central destination.
Improves data quality
Resolve defects in your data transformation process. Optimize data quality by processing, validating, and standardizing data, eliminating inaccuracies such as duplication and formatting issues.
Facilitates better analysis of big data
Need help converting large amounts of data into a structured format? A data pipeline enables more rigorous big data analysis, even from unstructured data sources.
Who Manages Data Pipelines?
Data pipelines require a deeper understanding of data management. It's primarily why technical managers are the ones who interact with the pipeline themselves.
Typical job titles:
- Data engineers and architects
- Data analysts
- Data scientists
- CIO/CTOs
The roles and responsibilities of these professionals in adjusting data pipelines vary for every organization.
Types of Data Pipeline Architectures
Data pipelines are built on three different architectures based on the nature of data:
Streaming Data
The continuous ingestion and processing of streaming data require tools to process real-time data from sources such as IoT devices, social media, and financial transactions.
This entails setting up an architecture that caters to real-time analytics and providing on-premises data science solutions. ELT pipelines can be used to optimize new data processing and minimize latency.
Batch Processing
For historical data, batch processing pipeline architecture is best for updating at set intervals.
This architecture is ideal for large workloads that require storing data analysis. Advanced data engineering tools such as SQL extract, transform, load, and store data accurately and efficiently. Basically, if you don't need to query a live data set, then batch data processing is a good option.
Hybrid Processing
Hybrid processing architecture processes real-time streaming data and stored data simultaneously. This approach is more complex since it requires segmenting stream processing and batch-processing jobs within the same pipeline.
A hybrid data ingestion engine optimally helps provide clear benefits to large organizations dealing with extensive amounts of real-time and historical data. The use of tools such as BigQuery and the extraction of new data are crucial components of hybrid processing.
Popular Data Pipeline Use Cases
Consolidating Data from Multiple Sources
Data often comes from several SaaS app sources, complicating data analysis. Data pipelines are used to gather all the necessary data in one place for analysis. This process defines the data flow and connectors for pushing it into a cloud data warehouse.
Automating Data Transformation
Different data sources often produce data in different formats. Converting that data entails extract, transform, load operations to prep the data for loading. Data pipelines define the automated and scheduled steps for synchronizing data.
Improving Business Intelligence
Raw data is unable to provide insights into business operations. Data pipelines convert raw and unstructured data into a centralized, structured format. This transformed data is analyzed to extract reliable information researchers can use to optimize their processes and make data-driven decisions.
Stages of a Data Pipeline
Step 1: Data Ingestion
This is the first step, where the data pipeline extracts data from various source systems, such as CRM, ERP software, SaaS apps, APIs, web apps, and IoT devices.
Step 2: Data Storage
The extracted data is stored in a temporary data lake or data warehouse so that all the required data is gathered in a single location for further processing. The main goal is to centralize raw data from separate sources before it can be processed.
Step 3: Data Transformation
The collected data is now processed according to the target system's specifications, removing duplications and fixing errors for better data quality, organizing different data points into a relational database, etc. There is no one-size-fits-all approach to altering the data. This stage can be tailored based on the data's type and format.
Step 4: Data Integration
The last step is to combine the data for a complete analysis. Through data integration, the pipeline establishes connections between various data points. Data integrations help furnish an entire dataset to deliver insights for business intelligence (BI) and analytics