
Learning Data Engineering
Data Engineering is still one of the most sought-after positions in the Tech industry at the moment.
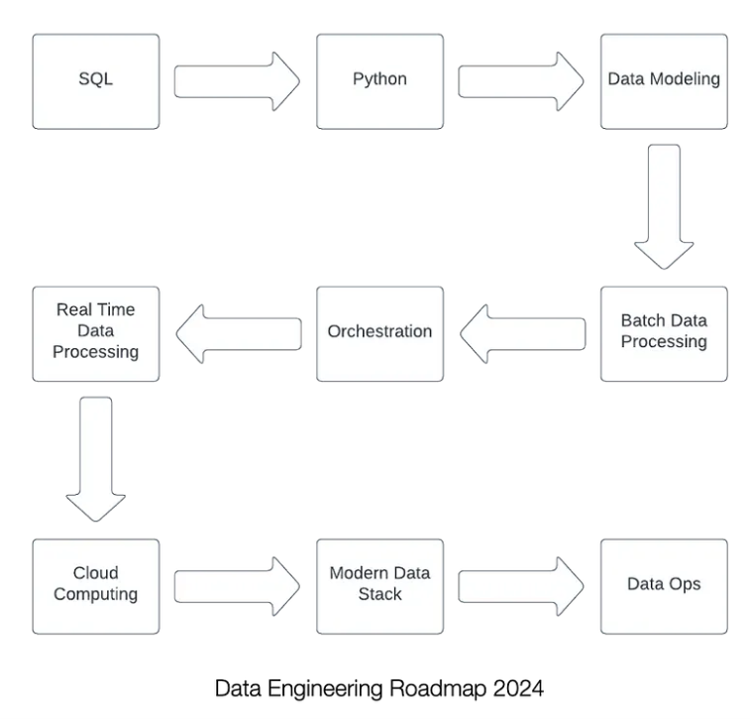
SQL (Must-know):
Start your journey with SQL which stands for Structured Query Language and is the de facto language to structure data for storage in data stores, wrangle it in motion and later access it from a data store for analytics. First, learn the basic commands of the language to query data from a database. Then learn how to filter data, followed by how to join data from multiple tables and aggregate data. Next, level up by learning SQL subqueries. Follow this by learning Data Definition Language (DDL) and Data Manipulation Language (DML) commands for structuring data in a database for subsequent efficient analytics querying. Advance to the expert level by learning the powerful concept of SQL window functions. Finally, practice SQL as much as you can to feel confident in interviews using platforms such as LeetCode.
Python (Must-know):
Next, become proficient in Python programming. Start with understanding the different data types and operators, control flow for building logic into your code using conditional statements and loops, data structures (lists, dictionaries, tuples and sets) for organizing your data, functions for reusing your code and Python libraries such as Pandas for data manipulation. Master this programming language by practicing problems in platforms such as LeetCode. If time permits, you can also learn another programming language such as Java or Scala, especially when dealing with massive data.
Dimensional Modelling (Must-know):
After developing the foundations, the third major step is to learn about dimensional modelling using a hands on learning approach. In this phase, learn about the difference between normalization and denormalization. Next, learn about the star schema, which is a denormalized data model optimized for analytical queries, fact and dimension tables and slowly changing dimensions (SCD). In this phase, also learn about the different data storage components, such as Data Warehouses and Data Lakes, which integrate with other components together to build robust data system and implement these data stores. Examples of popular Data Warehouses include Redshift, BigQuery and Snowflake and Data Lakes include S3.
Batch Data Processing (Must-know):
The fourth major milestone is achieved when you have understood about batch data processing, again using a hands-on approach. Data needs to be cleaned, enriched and wrangled when in motion from its different source systems to its target data store. Apache Spark is one of the most popular open-source frameworks for distributed processing of big data across a cluster of computers. Implement a big data processing solution using Apache Spark to get hands on experience with this technology.
Data Workflow Orchestration (Must-know):
In the next phase, learn about writing data pipelines as Directed Acyclic Graphs (DAGs) using Python with defined task dependencies and with the ability to automatically run on on a schedule or an event-based trigger using an orchestration tool such as the open-source Apache Airflow and implement it yourself. At this stage, you would have covered enough ground to interview with different types of organizations for a Data Engineer position.
Real-time Data Processing (Nice-to-know):
More recent patterns for data movement and transformation involve transitioning away from the batch paradigm and adopting the real-time paradigm in which data is streamed in real-time from various sources using a pub/subcomponent such as Apache Kafka and analyzed in real-time using a stream processing framework such as Apache Flink and Apache Storm. Implement real-time data pipelines to get hands-on experience.
Cloud Computing (Must-know):
Most of the organizations, big and small, enterprises and startups are increasingly leveraging Cloud Computing to migrate their existing data workloads or establish greenfield data platforms. Therefore, it is prudent to learn either Azure or AWS and validate your skills by achieving a foundational level Cloud Computing certification such as AWS’ Cloud Practitioner certification and thus communicate your knowledge and expertise in this area to potential employers.
Modern Data Stack (Optional):
The long existing paradigm in Data Engineering has been the Extract, Transform, Load (ETL) process because of the high storage and compute costs. However, in recent years since the rise of Cloud Computing, these costs have dropped significantly and led to the development of MPP and Columnar Cloud Data Warehouses (CDW) such as Redshift and the Extract, Load, Transform (ELT) paradigm. In this process, the data is transformed in place using the industry standard Transformation tool, Data Build Tool (dbt), after loading it in its raw form using popular Extract-Load tools such as Fivetran. These tools are collectively known as the Modern Data Stack (MDS) and an approach to the ELT process in a cost-effective, efficient and scalable manner. While not a requirement to become a great Data Engineer, MDS knowledge and skills will help you land the newer job position of an Analytics Engineer, which this paradigm has created.
Data Ops (Optional):
Similarly, Data Ops knowledge and skills are optional. The Data Engineering role has lots of manual tasks and thus with the popularity of Dev Ops in the software world and its role in promoting agility and automation in the process, Data Ops has seen similar benefits with this adoption. Data Ops involves the use of Continuous Integration and Continuous Delivery (CI/CD) pipelines and Infrastructure as Code (IaC) with Terraform to automate the manual tasks of Data Engineering.