
building an elt data pipeline for snowflake
Snowflake's ELT (Extract, Load, Transform) approach provides a flexible and scalable way to build data pipelines.
Building a business based on data can be challenging yet highly rewarding. But as you make the efforts to make the best use of your business data, it is necessary to educate yourself on the optimal methods to do it.
General process for building data pipelines using Snowflake's ELT:
- Understand Data Sources and Requirements: Identify the data sources you want to integrate into Snowflake and understand their structure, format, and data quality. Determine the specific requirements and goals of your data pipeline, such as data transformations, aggregations, or data quality checks.
- Extract Data: Extract data from the source systems using Snowflake's data loading utilities or other relevant tools. Snowflake supports various data ingestion methods, including bulk data loading, streaming, or using external stages. Extract the necessary data while ensuring data security and integrity.
- Load Data into Snowflake: Load the extracted data into Snowflake. Snowflake provides options such as SnowSQL, Snowpipe, or Snowflake connectors to facilitate data loading. Choose the appropriate method based on your data volume, frequency, and integration requirements. Ensure data consistency and maintain appropriate data structures within Snowflake, such as tables and schemas.
- Design Data Transformation Processes: Snowflake's ELT approach emphasizes transforming data within the platform rather than before loading. Determine the data transformations and processing logic required for your pipeline. This may involve SQL queries, stored procedures, or Snowflake's built-in functions. Leverage Snowflake's powerful SQL capabilities to perform data transformations efficiently.
- Build Transformation Workflows: Design the workflows that orchestrate the data transformations within Snowflake. This can be achieved using Snowflake's task and scheduling features, external workflow tools like Apache Airflow or AWS Step Functions, or custom scripts. Define the dependencies, sequence, and frequency of transformations to ensure the pipeline runs smoothly and efficiently.
- Validate and Cleanse Data: Implement data validation and cleansing processes within Snowflake to ensure data quality. Use SQL queries or Snowflake's built-in data validation functions to check for anomalies, errors, or missing values. Identify and handle data quality issues to maintain the accuracy and reliability of the integrated data.
- Implement Incremental Loading: If your pipeline requires incremental loading to keep the data up to date, define mechanisms to identify and load only the changed or new data. Use Snowflake's unique capabilities like time travel, streams, or change data capture (CDC) techniques to efficiently handle incremental updates.
- Schedule and Automate the Pipeline: Establish a schedule and automation mechanism for running the data pipeline. Snowflake offers features like tasks, time-based or event-based triggers, and integration with external workflow tools to automate the pipeline execution. Set up monitoring and error handling processes to ensure the pipeline runs reliably and notifies stakeholders in case of failures.
- Enable Data Consumption: Make the integrated data available for consumption by connecting business intelligence (BI) tools, data visualization platforms, or other downstream systems to Snowflake. Leverage Snowflake's integration capabilities with popular BI tools to enable self-service analytics and reporting on the integrated data.
- Monitor and Optimize: Continuously monitor the performance and efficiency of your data pipeline. Leverage Snowflake's monitoring tools, query history, and performance optimization features to identify bottlenecks or areas for improvement. Regularly review and refine your pipeline to adapt to changing data sources, business requirements, and evolving best practices.
What is a data pipeline?
A data pipeline is a collective term used to denote the various stages data moves through from a source to its destination.
- Be it any workflow or a process, data goes through certain transformations as necessary to prepare it for its destination.
• Data is either stored or used to generate more data at the end of the pipeline.
• Successful data pipeline execution involves a multitude of steps. The tasks such as data ingestion,
- extraction, transformation, enrichment, aggregation, and more could be executed in a data pipeline sequence.
Raw data enters the data pipeline, goes through these various stages of data operations, and reaches the target destination at the end of the process. - Data engineering aims to optimize these data pipelines to be reliable and easy to execute with minimal effort.
- When the output of the data pipeline remains unchanged and can be repeated without any changes in the stages, it's the perfect candidate for automation through ELT and ETL tools.
- How your data pipelines are designed determines your data systems' overall performance and data integration strategies.
elt vs etl
ELT is often considered an upgrade over the previously used
ETL data pipelines as it reduces the complexity of running transformations before the loading process. And in some cases,
ELT is used along with ETL to improve the overall data integration results.
ELT also helps streamline the data pipelines as the transformation process is moved to a later point. While ELT may not be suitable for cases where the target system expects a specific data format, it is well suited for cloud-based warehouses such as the Snowflake.
Some other instances in which ELT might not be the best choice include:
- Security requirements that restrict storing raw data as is
- Target systems that enforce strict data types and formats
- Quick scaling up of the loading process in a destination
- If not for these concerns, ELT can be a good choice for building data pipelines, especially for cloud-native data solutions like Snowflake, Google BigQuery, Amazon Redshift, AWS Lambda, Azure SQL, etc.
Benefits of let for cloud-based data warehouses
Fast turnaround time — ELT speeds up the data processes. It moves the time-consuming transformation process to the last stage after data integration, thus allowing business intelligence (BI) tools to access data much faster.
Scalability — ELT works great with cloud-based solutions with auto-scale features, as it can take advantage of a cloud environment's vast resources.
Flexibility — ELT data pipelines allow more flexibility for the BI tools to run transformations on demand. So after data ingestion, data can be transformed depending on the requirement as and when needed, unlike ETL, where data is already changed and offers less flexible options after the loading stage.
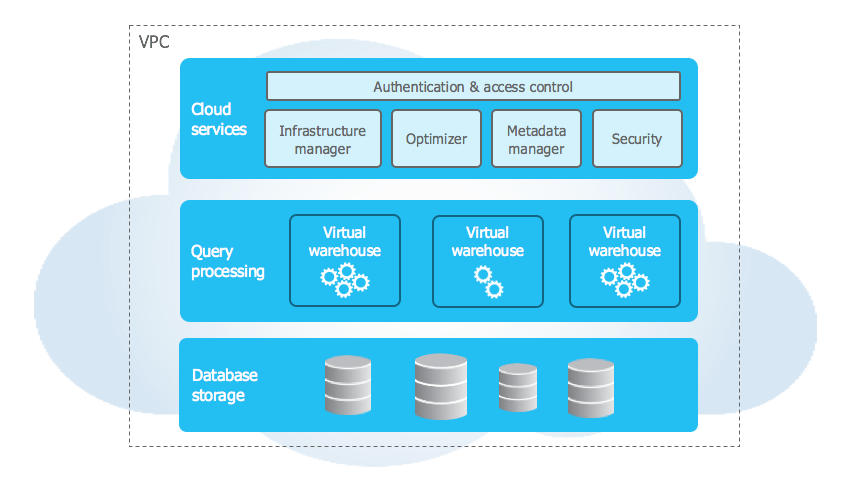
What is a snowflake data warehouse?
- Snowflake is a cloud-based data warehouse SaaS-based solution that can work with all major cloud platforms, such as Amazon Web Services, Azure, and Google Cloud.
- It is quite a unique data warehouse with a considerable performance advantage compared to many other data warehouse solutions.
- Snowflake allows for unlimited virtual warehouses, each capable of quick resizing, thus allowing you to adjust your configurations per your workload.
- It also provides impressive scalability with its multi-cluster support.
- Users need only pay for the resources they use, and based on the load, the multi-cluster features automatically scale up and down as required. This is made possible by the EPP database architecture that Snowflake pioneered.
- The Snowflake data warehousing service consists of three layers: service, compute, and storage.
- The service layer handles the database connectivity, concurrency, and data management of metadata and transactions.
- The compute layer handles the virtual warehouses.
- The storage layer deals with the huge data pool.
- Snowflake also uses the Massively Parallel Processing (MPP) architecture, where a cluster of independent machines is deployed, and the data is distributed across the system.
- The version of MPP used by Snowflake is called EPP or Elastic Parallel Processing, which gives the advantage of quickly starting new clusters. It allows for an elastic way to scale up and down the resources as and when required.
building an elt data pipeline for snowflake
- Data pipelines are essential to provide a streamlined data integration process. They give you a better idea of where the data comes from, the processes and transformations run on the data, and the applications and use cases where it is utilized.
- Data pipelines help better utilize your data analytical apps, as gathering data from multiple spreadsheets, invoices, and reporting documents will be a colossal challenge otherwise.
- When you opt for a cloud-based solution such as Snowflake, using an ELT data pipeline is best.
- Snowflake data cloud, a cloud-based solution, can provide highly scalable access to resources. Thus, it is best suited for running transformations after loading so that you get more flexibility with the types of modifications to run on the data as well as scalability to run the otherwise resource-expensive data transformations. Thus, data analytical apps and BI tools can also take in the raw data and transform it as required to gather better insights.
- As transformation is moved to a later stage, ELT provides a streamlined process that ensures standard outputs as the data is loaded into the snowflake data lake.
choose your data integration tool
The first step to building a data pipeline is identifying the data sources. Once your new data sources are ready, you need a proper data integration tool to extract data from multiple sources.
Here are several factors to consider when choosing a data integration tool:
- Data platform compatibility with Snowflake data warehouse — Confirm that the data integration tool works with your selected data warehouse. The good news here is that Snowflake is widely supported.
- Extensive data connector library — A data connector extracts data from a particular source. Ensure your data integration tool has the necessary support for the data connectors you need. If not, look into any support for custom data connectors. You can also validate data connectors to support normalization and standardization based on their features.
- Supports automation — Use tools that help you minimize any manual effort in the data pipeline process. Scheduled data syncs are superior to manual sync.
- ELT support — Check if the tool supports ELT data pipelines to run the transformations in the Snowflake data warehouse.
- Data recovery functionality — Choosing robust tools that can help you quickly recover data in case of a failure is always a good idea.
- Security and compliance — Ensure the data integration tool meets data standards and regulations. You should also look into the security features to avoid leaking sensitive data and prevent unauthorized access.
Some qualities you should be looking for in your BI tools include:
- Easy integration with Snowflake data warehouse
- Intuitive UI with easy-to-use options like drag-and-drop interfaces
- Support for real-time data
- Automation support for reporting and alerts
- Support for ad hoc reports based on exported data files
- Good performance and responsiveness
- Flexibility for data modeling and development teams
- Visualizations library for a better understanding of the data reports
best elt pipeline tools
1. Hevo
Hevo is a no-code ELT data pipeline tool with 100+ data connectors. It is compatible with Snowflake and uses a Models-and-Workflows approach to move data into the data warehouse.
Hevo offers a tiered subscription plan under three tiers, free, starter, and business. The free plan supports unlimited data sources, which is quite impressive. The starter plan is priced starting from $249 per month. As you scale up your resources, the pricing also goes up.
2. Blendo
With over 40+ connectors, Blendo is a well-known data integration tool offering ELT data pipeline support. It is best suited for businesses moving data from social media ad accounts like Facebook, LinkedIn Ads, MailChimp, and similar channels to a cloud-based cloud data warehouse.
Blendo's plans start from $150 per month. Their advanced plan is priced at $500 monthly and includes more than 150 pipelines.
3. Matillion
- Matillion is a data integration tool specifically built to support cloud-based data warehouses and ELT pipelines. It is a performance-optimized tool that helps offload resource-intensive tasks from your on-premises servers.
- Matillion follows a pay-as-you-go model where you pay per hour without long-term financial commitments. Starting price is $1.37 per hour, which can go up to $5.48 per hour for larger teams and high workloads.