
FIVE CHARACTERISTICS OF A MODERN DATA PIPELINE
FIVE CHARACTERISTICS OF A MODERN DATA PIPELINE
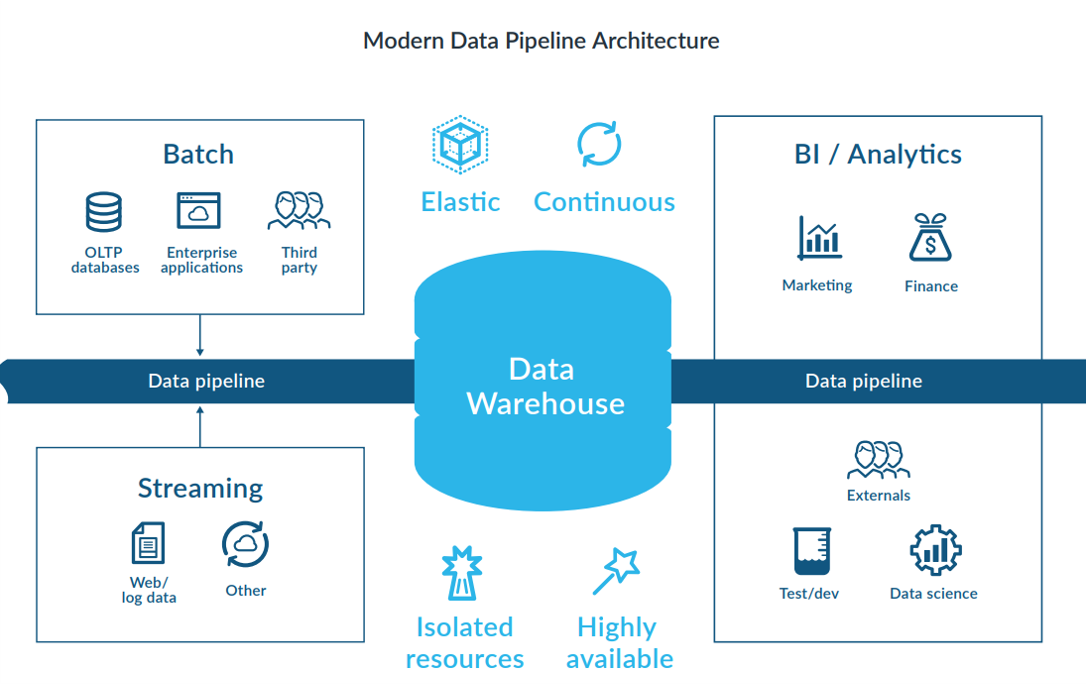
- CONTINUOUS AND EXTENSIBLE DATA PROCESSING
The scourge of stale data
Traditionally, organizations extract and ingest data in prescheduled batches, typically once every hour or every night. But these batch-oriented extract, transform, and load (ETL) operations result in data that is hours or days old, which substantially reduces the value of data analytics and creates missed opportunities. Marketing campaigns that rely on even day-old data could reduce their effectiveness. For example, an online retailer may fail to capture data that reveals the short-term buying spree of a certain type of product based on a celebrity discussing, using, or wearing the product.
Modern data pipelines can also incorporate and leverage custom code that is written outside the platform. Using APIs and pipelining tools, they can stitch together a data flow using outside code seamlessly, avoiding complicated processes and maintaining the low latency.
2. THE ELASTICITY AND AGILITY OF THE CLOUD
Modern data pipelines offer the instant elasticity of the cloud and a significantly lower cost structure by automatically scaling back compute resources as necessary. They can provide immediate and agile provisioning when data sets and workloads grow. These pipelines can also simplify access to common shared data, and they enable businesses to quickly deploy their entire pipelines without the limits of a hardware setup. The ability to dedicate independent compute resources to ETL workloads enables them to handle complex transformations without impacting the performance of other workloads.
3. ISOLATED AND INDEPENDENT RESOURCES FOR DATA PROCESSING
An architecture in which compute resources are separated into multiple independent clusters. In addition, the size and number of those clusters can grow and shrink instantly and nearly infinitely depending on the current load. All the while, each cluster has access to the same shared data set that they jointly process, transform, and analyze. Such an architecture has become crucial and cost-effective for today’s organizations, thanks to cloud computing.
A modern data pipeline that features an elastic multi-cluster, shared data architecture makes it possible to allocate multiple and independent isolated clusters for processing, data loading, transformation, and analytics while sharing the same data concurrently without resource contention.
4. DEMOCRATIZED DATA AND SELF-SERVICE MANAGEMENT
Modern data pipelines democratize data by increasing users’ access to data and making it easier to conceptualize, create, and maintain data pipelines. They also provide the ability to manage all types of data, including semi-structured and unstructured data. With true elasticity and workload isolation, and advanced tools such as zero-copy cloning, users can more easily massage data to meet their needs.
A modern data pipeline supported by a highly available cloud-built environment provides quick recovery of data, no matter where the data is or who the cloud provider is. If a disaster occurs in one region or with one cloud provider, organizations can immediately access and control the data they have replicated in a different region or with a different cloud provider.
5. HIGH AVAILABILITY AND DISASTER RECOVERY
If an internet outage occurs due to network issues, natural disasters, or viruses, the financial impact of downtime can be significant. Corporate and government mandates also require the durability and availability of data, and proven backup plans are necessary for compliance. However, fully restoring data and systems is time-consuming and leads to the potential of lost revenue.