
Snowflake as a Data Warehouse
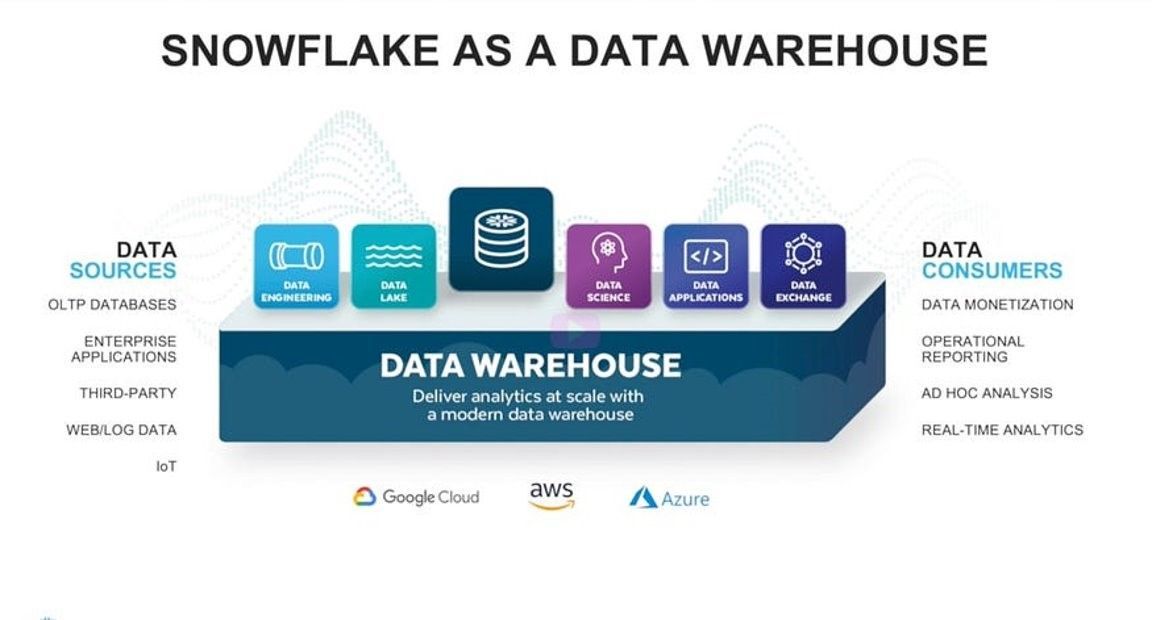
A data warehouse is created by extracting, transforming, and loading data from various operational systems and sources into a central database. The data is organized into subject areas, such as sales, finance, or marketing, and is typically optimized for querying and analysis. The process of creating a data warehouse is known as ETL (extract, transform, load).
Legacy Data Warehouse challenges —
As you all know, legacy warehouse systems had challenges and cloud-based solutions can help to reduce and overcome some of these challenges. Typical challenges include —
- Infrastructure Limitations — limited or provisioned or pre-purchased Compute and Storage capacity.
- Data Sharing and Consistency — Data sharing with consumer applications and eventual consistency.
- Data Security — Data classification, data masking, encryption, and security
- Operations and Maintenance — High maintenance cost and operational dependencies
- Technology limitations — Specific tools, and technologies to develop products and features. Skilled resource dependencies
Snowflake as a Data Warehouse
- Cloud-based solutions help to reduce these challenges however they impose some of the new challenges or still follow the old school to implement data warehousing solutions. In most cases, these solutions are specific to the hyperscalar and support native managed services and integrations.
- Snowflake is built from scratch on the cloud and offers a variety of solutions based on the workload, type of data, type of sources, and consumers. Snowflake supports various workloads — Data Warehouse, Data Lake, Lakehouse, and Unistore. This blog is focusing on warehouse workload and architecting options with Snowflake.
To architect a data warehouse on Snowflake, you can consider following some of these key steps —
- Define Your Requirements: It’s important to define your requirements. This includes identifying the types of data you need to store, the data sources you will be using, and the types of analytics and reporting you will be performing.
- Design Your Data Model: Once your requirements are finalized, you can begin designing your data model. This involves creating a logical schema that defines the relationships between your data tables and the data types for each field.
- Create Your Data Warehouse: After the data model design, you can begin creating your data warehouse. Snowflake provides a cloud-based data warehouse platform that allows you to quickly and easily provision data storage, compute resources, and other necessary components.
- Load Your Data: Once your data warehouse is created, you can begin loading your data. Snowflake supports a variety of data loading options, including bulk loading, streaming, and real-time data ingestion.
- Analyze Your Data: With your data loaded into Snowflake, you can begin analyzing your data using SQL queries or business intelligence tools. Snowflake provides a powerful SQL engine that supports advanced analytics and reporting capabilities.
- Optimize Your Data Warehouse: As you begin working with your data warehouse, you may find that certain queries or operations are slow or inefficient. Snowflake provides several optimization tools and techniques to help you improve performance and reduce costs.
Data Warehouse with Snowflake Architecture Design —
You can design your warehouse with ETL or ELT patterns. Snowflake can be hosted on any cloud — AWS, GCP, and Azure. You can integrate it with any other cloud with its native integrations and access files across the cloud. Snowflake offers support and integration with various ETL, ELT, and BI tools.
ETL Pattern: This pattern approach can be implemented with Snowflake partner tools. In this example, you can use Matillion, and Informatica to design and develop your load processes or data pipelines. You can also use dbt which is also referred to as ELT as it supports orchestration of the pipelines that can be executed on Snowflake.
Source Integrations —
You can integrate all types of sources — File, Dbases, real-time, SAP, Salesforce, etc. Snowflake also supports cross-cloud access where you can configure data storage buckets or containers to pull data as a source. You can also use ETL tools on top of native-supported features to integrate source systems.
Engineering Loads —
You can design workloads, and data pipelines using Snowflake native objects or using dbt, matillion, or other third-party tools. Snowflake supports ANSI SQL standards, and you can create SQL jobs, Stored procedures to develop data transformation jobs. If you want to use a programmatic way, you can use Snowpark — Scala, Java, and Python supported pipelines.
Consumer Integrations —
Similar to source integrations, Snowflake consumer integrations are easy to implement with Data Sharing. You can have data shared with Snowflake and non-Snowflake consumer users with security and strong consistency without any additional pipelines, processes, etc.
Snowflake also supports most of the BI tools. These can be integrated for data analytics and run queries, and jobs on Snowflake. Snowflake extends support to machine learning implementations with Snowpark. Snowpark can be used for Data Engineering as well as Data Science solutions. Snowpark plays an important role while designing workloads.
Snowflake is highly differentiated as a data warehouse because of these reasons and supported features -
- Unlimited Scaling and Concurrency
- Fast Auto-scaling
- Near Zero Administration
- ANSI SQL support
- Native semi-structured data
- Cross-region + Cross cloud