
Big Data Analytics Tools
Big Data Analytics the process of collecting, processing, and analyzing large and complex datasets to uncover patterns, trends, and insights that can inform business decisions. It involves using specialized software tools and technologies to handle massive amounts of structured and unstructured data from various sources such as social media, mobile devices, sensors, and more.
The main goal of Big Data Analytics is to extract value from data by uncovering hidden insights that can help organizations make better decisions, improve operational efficiency, and create new business opportunities.
Big data analytics is important because it allows data scientists and statisticians to dig deeper into vast amounts of data to find new and meaningful insights. This is also important for industries from retail to government as they look for ways to improve customer service and streamline operations.
The importance of big data analytics has grown along with the variety of unstructured data that can be mined for information: social media content, texts, click data, and the multitude of sensors from the Internet of Things.
Big data analytics is essential because traditional data warehouses and relational databases cannot handle the flood of unstructured data that defines today’s world. Best suited for structured data. They also cannot handle real-time data requests. Big data analytics fulfils the growing demand for real-time understanding of unstructured data. This is especially important for companies that rely on rapidly changing financial markets and web or mobile activity volume.
Businesses understand the importance of big data analytics to help them find new revenue opportunities and improve efficiencies that provide a competitive advantage.
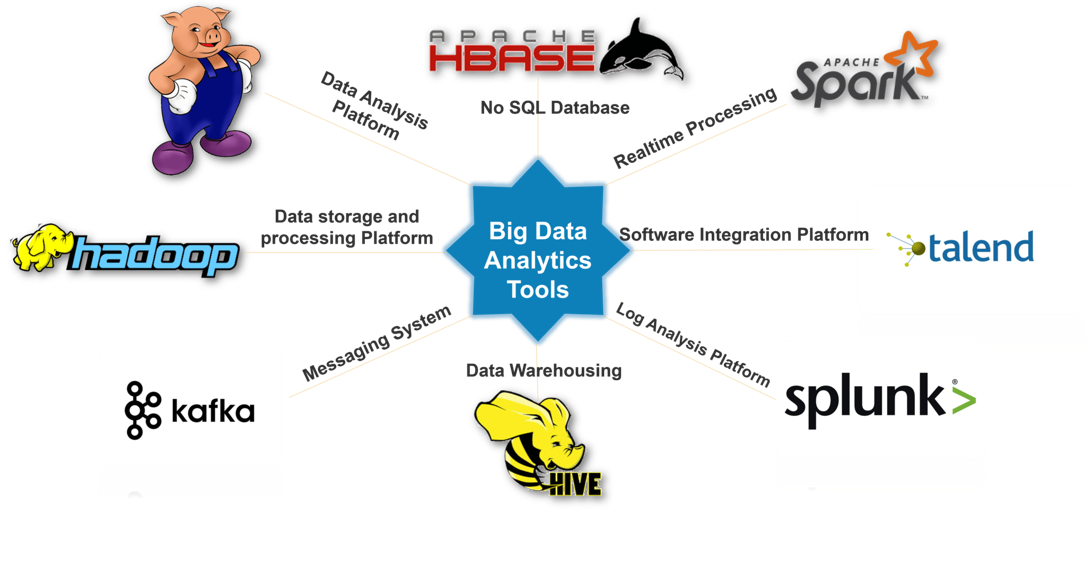
Big Data Analytics Tools
- Apache Hadoop: Hadoop is an open-source framework that is widely used for storing and processing large datasets. It uses a distributed file system and MapReduce programming model to enable parallel processing of large datasets.
- Apache Spark: Spark is a fast and scalable data processing engine that supports a wide range of data sources and processing models. It is commonly used for batch processing, real-time processing, and machine learning.
- Apache Kafka: Kafka is a distributed streaming platform that is widely used for real-time data processing and messaging. It enables high-throughput, low-latency data processing and can be integrated with other data processing frameworks such as Hadoop and Spark.
- Tableau: Tableau is a data visualization tool that enables users to create interactive dashboards and visualizations from large datasets. It supports a wide range of data sources and provides a user-friendly interface for data exploration and analysis.
- R: R is a programming language that is widely used for statistical computing and graphics. It provides a wide range of statistical and graphical techniques and is commonly used for data exploration, analysis, and visualization.
- Python: Python is a popular programming language that is widely used for data analysis, machine learning, and scientific computing. It provides a wide range of libraries and frameworks for data analysis and processing, including NumPy, Pandas, and Scikit-Learn.
- IBM Watson: IBM Watson is an AI-powered platform that enables users to build, deploy, and manage AI models and applications. It provides a wide range of AI services, including natural language processing, speech recognition, and image analysis.
10 Key Technologies that enable Big Data Analytics for businesses
1) Predictive Analytics
One of the prime tools for businesses to avoid risks in decision making, predictive analytics can help businesses. Predictive analytics hardware and software solutions can be utilised for discovery, evaluation and deployment of predictive scenarios by processing big data. Such data can help companies to be prepared for what is to come and help solve problems by analyzing and understanding them.
2) NoSQL Databases
These databases are utilised for reliable and efficient data management across a scalable number of storage nodes. NoSQL databases store data as relational database tables, JSON docs or key-value pairings.
3) Knowledge Discovery Tools
These are tools that allow businesses to mine big data (structured and unstructured) which is stored on multiple sources. These sources can be different file systems, APIs, DBMS or similar platforms. With search and knowledge discovery tools, businesses can isolate and utilise the information to their benefit.
4) Stream Analytics
Sometimes the data an organisation needs to process can be stored on multiple platforms and in multiple formats. Stream analytics software is highly useful for filtering, aggregation, and analysis of such big data. Stream analytics also allows connection to external data sources and their integration into the application flow.
5) In-memory Data Fabric
This technology helps in distribution of large quantities of data across system resources such as Dynamic RAM, Flash Storage or Solid State Storage Drives. Which in turn enables low latency access and processing of big data on the connected nodes.
6) Distributed Storage
A way to counter independent node failures and loss or corruption of big data sources, distributed file stores contain replicated data. Sometimes the data is also replicated for low latency quick access on large computer networks. These are generally non-relational databases.
7) Data Virtualization
It enables applications to retrieve data without implementing technical restrictions such as data formats, the physical location of data, etc. Used by Apache Hadoop and other distributed data stores for real-time or near real-time access to data stored on various platforms, data virtualization is one of the most used big data technologies.
8) Data Integration
A key operational challenge for most organizations handling big data is to process terabytes (or petabytes) of data in a way that can be useful for customer deliverables. Data integration tools allow businesses to streamline data across a number of big data solutions such as Amazon EMR, Apache Hive, Apache Pig, Apache Spark, Hadoop, MapReduce, MongoDB and Couchbase.
9) Data Preprocessing
These software solutions are used for manipulation of data into a format that is consistent and can be used for further analysis. The data preparation tools accelerate the data sharing process by formatting and cleansing unstructured data sets. A limitation of data preprocessing is that all its tasks cannot be automated and require human oversight, which can be tedious and time-consuming.
10) Data Quality
An important parameter for big data processing is the data quality. The data quality software can conduct cleansing and enrichment of large data sets by utilizing parallel processing. These software's are widely used for getting consistent and reliable outputs from big data processing.