
Folders organization in Data Lake
Data Warehouse
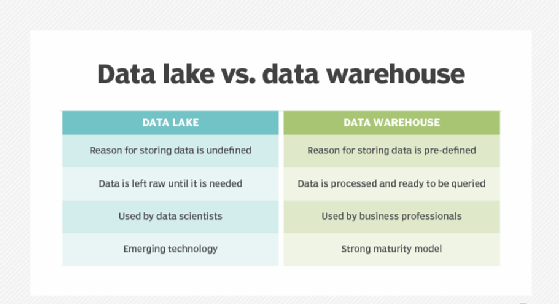
- A data warehouse is a centralized repository of integrated, structured, historical data from various sources within an organization. It is designed to support business intelligence (BI) and analytical processes, enabling organizations to make informed decisions based on a holistic view of their data. Data warehouses provide a foundation for data analysis, reporting, and data mining, allowing users to extract insights and patterns from large datasets.
- The common design of data warehouses incorporates a staging area where raw data is extracted from various sources using ETL tools like Informatica PowerCenter, SSIS, Data Stage, Talend, and more. The extracted data is then transformed into a data model within the data warehouse, either using an ETL tool or SQL statements. There are several architectural approaches to design a data warehouse, including the Inmon, Kimball, and Data Vault methodologies.
Modern Data Warehouse
A modern data warehouse is an evolved and technologically advanced version of the traditional data warehouse, designed to handle the challenges posed by the ever-increasing volumes of data, diverse data sources, and the need for real-time analytics. It leverages modern technologies and architectures to provide greater agility, scalability, and flexibility in data management and analytics.
Two-tier Data Warehouse: Pros and Cons
Advantages:
- Data is structured, modeled, cleaned, and prepared.
- Easy access to data.
- Optimized for reporting purposes.
- Column and row-level security, data masking.
- ACID transaction support.
Disadvantages:
- Complexity and time-consuming for changes in implementation in the data model and the ETL process.
- Schema must be defined.
- Costs of the platform (depends on the database provider and type).
- Database vendor dependence (Complex in a migration from, for instance, Oracle to SQL Server).
Data Lake History
- Early Data Warehousing (1980s - 2000s): In the early days of data management, organizations relied on data warehouses to store and analyze structured data. These data warehouses were optimized for structured data, and data had to be cleaned, transformed, and loaded before it could be analyzed.
- Rise of Big Data (Mid-2000s - Early 2010s): With the explosion of digital data from various sources like social media, sensors, and logs, the limitations of traditional data warehouses became apparent. Organizations faced challenges in handling unstructured and semi-structured data. Technologies like Hadoop emerged to address these challenges, providing distributed storage and processing capabilities.
- Introduction of Hadoop and NoSQL (Early 2010s): Hadoop, an open-source framework, introduced the idea of distributed storage (HDFS) and processing (MapReduce) for big data. This allowed organizations to store and process vast amounts of data across commodity hardware. NoSQL databases also gained popularity for their ability to handle diverse data types and high-speed data ingestion.
- Birth of the Data Lake (Mid-2010s): The concept of the data lake emerged as a response to the limitations of traditional data warehousing and the growing need for handling large volumes of diverse data. Data lakes aimed to store raw, unprocessed data in its native format, allowing organizations to store data without upfront transformation.
- Focus on Schema on Read (Late 2010s): Unlike traditional data warehouses that employed "schema on write," where data had to be transformed and structured before ingestion, data lakes focused on "schema on read." This means data could be ingested as-is and structured and transformed when it's read for analysis.
- Evolution of Cloud Services (2010s - Present): Cloud computing played a significant role in the evolution of data lakes. Cloud-based data lakes allowed organizations to scale storage and processing resources dynamically, making it easier to manage data growth and handle large workloads.
- Advancements in Data Lake Management (Present): Today, data lakes incorporate advanced data management tools, metadata management, data governance, and security controls. Organizations can integrate data lakes with machine learning and analytics tools for deriving insights from diverse data sources.
- Integration with Traditional Data Warehousing (Present): Organizations recognize that data lakes and data warehouses serve different purposes. They have started integrating data lakes with traditional data warehouses, creating hybrid architectures that leverage the strengths of both paradigms.
- Focus on Data Lake Governance (Present): As data lakes grow in complexity and scale, there's an increased emphasis on data governance, ensuring that data stored in the lake is well-managed, compliant, and secure.
Folders organization in Data Lake
To prevent the occurrence of a data swamp, it is essential to establish a simple and self-descriptive folder structure within the data lake. A proper hierarchical structure should be implemented, ensuring that folders are human-readable, easily understandable, and self-explanatory. It is crucial to define naming conventions prior to initiating the data lake development process.
These measures will facilitate the appropriate utilization of the data lake and aid in access management. Additionally, it is important to understand how to construct the folder structure to enhance the query engine’s comprehension of the data. The recommended approach is to organize data in the manner presented within the bronze and silver layers.
Data Lakehouse
- A data lakehouse is a relatively new architectural concept that combines the benefits of both data lakes and data warehouses. It aims to address the limitations and challenges of each paradigm by creating a unified platform for storing, processing, and analyzing data. The data lakehouse architecture seeks to provide the scalability and flexibility of data lakes along with the structure and performance of data warehouses.
- To implement the Lakehouse architecture, Databricks has developed a new type of file format called Delta (further details on file formats will be described later in this post). However, as alternatives to Delta, other file formats such as Iceberg and Apache Hudi can be utilized, offering similar features. These new file formats empower Spark to leverage new data manipulation commands that improve data loading strategies. In the Data Lakehouse, updates to rows in a table can be performed without the need to reload the entire dataset into the tables.
Data Lakehouse Architecture
Data Lakehouse organizes data mostly using the medallion architecture. As I mentioned we have three layers of data lakehouse Bronze, Silver, and Gold. The main difference in the case of data Lakehouse will be the file format.
The Bronze use to ingest data from sources “as-is”. Data is source-system aligned and organized in the storage. If we import data from sources we will save it in Delta format. Data can be ingested by ingestion tools and saved in its native format if it doesn’t support Delta or when source systems dump data directly into storage.
The Silver keeps data that were cleaned, unified, validated, and enriched with reference data or master data. The preferable format is Delta. Tables still correspond to source systems. This layer can be consumed by Data Sciences, ad-hoc reporting, advanced analytics, and ML.
The Gold layer hosts a data model that will be utilized by business users, BI tools, and reports. We use the Delta format. This layer keeps business logic that includes calculations and enrichment. We can have only a specific set of data from Silver or only aggregate data. The structure of tables is subject-oriented in this layer.