
Why DataOps?
Why DataOps?
- The need for DataOps stems from data governance. Gartner estimates that poor data quality resulting from subpar data governance structure costs companies $15 million per year on average.
- Furthermore, the onus of securing the data companies collect and process falls on the companies themselves. Failing to do so attracts hefty fines from regulators. Google was fined €57 million by French lawmakers for non-compliance with GDPR rules.
What is DataOps?
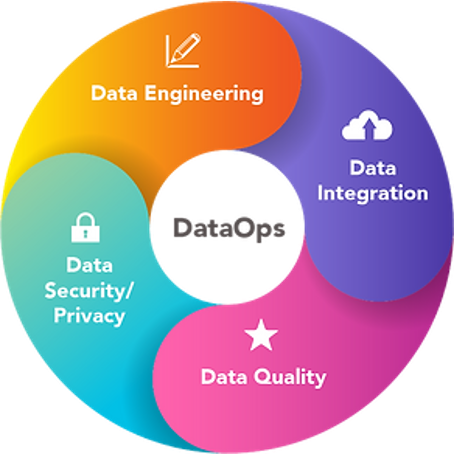
- DataOps, a combination of Data and Operations, refers to developing and managing data pipelines. It combines the 3P — people, process, and products — just like DevOps combines development with IT operations to enable better data management within an organization.
- But DataOps is more than two or three teams coming together. It's a new approach that changes the way businesses manage data.
- Andy Palmer, the CEO of Tamr, popularized the term DataOps. In an article published in 2015, he explained DataOps as a way to manage data in today's complex world, where crucial decision-making is driven by data.
These are grave mistakes that hurt your business value.
With the rise of big data and machine learning, traditional data governance practices like manual version control and metadata control are no longer feasible. You must have a more automated way of managing data flows, which is where DataOps comes into play.
DataOps brings the rigor necessary to modern data pipeline challenges. This is similar to how DevOps bought rigor to software development a decade or so ago.
All in all, here's why DataOps is rising in importance across the board:
- Better speed — DataOps reduces human errors at scale. This speeds up data transformation processes and allows operations teams to complete projects faster.
- Reliability — Along with speed, this approach grants data reliability. Traditionally, data science teams had to worry about the reliability of processed data. But DataOps solves that problem.
- More control — Teams gain more control over the data they process, eliminating silos. When working with different teams, proper data duplication or contamination can occur. But not anymore with the DevOps approach.
- More collaboration — Just like DevOps, DataOps brings working groups together. Data analysts collaborate through the Entire Data Lifecycle and ensure everyone is on the same page. No wonder why lean manufacturing managers prefer such collaborative approaches.
- Avoid non-compliance — DataOps will help you stay in compliance with the regulatory bodies. Its holistic approach to managing and storing data is core to what regulators need organizations to do: protect consumers' data.
Principles of DataOps
When it comes to DataOps, it has the following set of principles (as defined by Andy Palmer in his book, Getting DataOps Right):
- Open — Embrace open-source technologies and adopt the relevant open-source standards. This makes it easier for companies to adopt while lowering the cost. This also avoids lock-ins with a particular vendor, not at least for the long term.
- Highly automated — Automation is a key principle streamlining many tasks within data governance, like data pipelines, quality checks, monitoring, etc.
- Implements best-of-breed tools — DataOps approach forces teams to use the best tools for all data jobs. Moreover, the tools will be different for different jobs. DataOps keeps the team on their toes when selecting the tools for their tasks.
- Layered interfaces — If you need to work with multiple levels of abstraction (raw vs. aggregated data, for example), DataOps can offer a layered approach. This increases efficiency and allows teams to maintain data pipelines.
- Tracking data lineage — Tracking data lineage is like tracking software versions in DevOps. DataOps borrows the same concept and allows teams to keep track of the data lineage. With this knowledge, stakeholders can understand how and when data was generated, collected, processed, and updated.
- Space probabilistic data integration — DevOps has multiple data integration options. This grants more flexibility to data teams and allows them to pick the best approach.
- Combine aggregated and federated access methods — No two data management tasks are created equal. You must pick the best approach. With DataOps, you get to choose the best storage and access methods. Aggregated (where data is stored in one place) and federated (data stored in multiple places) are two storage types.
- Data processing in batch and streaming modes — Some projects are suited for batch processing, while others are for streaming processing. DataOps is designed to handle both data models. Batch processing is better for analytics where a large amount of data is involved.
- DataOps may (and will) evolve in the future. But the principles described above will stay the same. They will always define a DataOps ecosystem.
How to Get Started with DataOps? (The DataOps Framework)
Any data-driven organization must have DataOps in place. Traditional data management is no longer viable. To get started, you need to follow the DataOps Framework and follow these steps:
- Define goals — Give an aim to your data science project and define the goals. This will remind you and the analytics team why the project is being undertaken. Along with goals, define the key metrics you'll use to track the undertaking's progress, successes, and failures.
- Get upper management involved — DataOps is something that's going to impact many aspects of the business. And it'd require you to do things differently. Therefore, it's necessary to have the senior shareholders involved and get their buy-ins. Get everyone on the same page to avoid bottlenecks.
- Create teams with cross-functional roles — Like DevOps, DataOps is a collaborative project. Therefore, you should have cross-functional development team members with years of experience and divide them into teancorporate Agile methodologies — DataOps is about making your business more agile. So, you must adopt the agile methodologies and break down the project into several phases.
- Automate repetitive tasks — As already mentioned, automation is a core principle of DataOps. As far as possible, you should automate tasks and avoid repetition. Look upon artificial intelligence and machine learning for automation.
- Create a company-wide data governance policy — Data governance policy outlines the steps, procedures, and guidelines for handling data within an organization. It must apply to everyone in the organizational structure based on their roles. Creating such a policy is also crucial from a regulation point of view.
- Incorporate Agile methodologies — DataOps is about making your business more agile. So, you must adopt the agile methodologies and break down the project into several phases.
- Automate repetitive tasks — As already mentioned, automation is a core principle of DataOps. As far as possible, you should automate tasks and avoid repetition. Look upon artificial intelligence and machine learning for automation.
- Create a company-wide data governance policy — Data governance policy outlines the steps, procedures, and guidelines for handling data within an organization. It must apply to everyone in the organizational structure based on their roles. Creating such a policy is also crucial from a regulation point of view.
- Measure and monitor
Once the DataOps ecosystem is up and running, you must measure the progress and monitor everything end-to-end. This is where setting goals and KPIs will give you further guidance.