
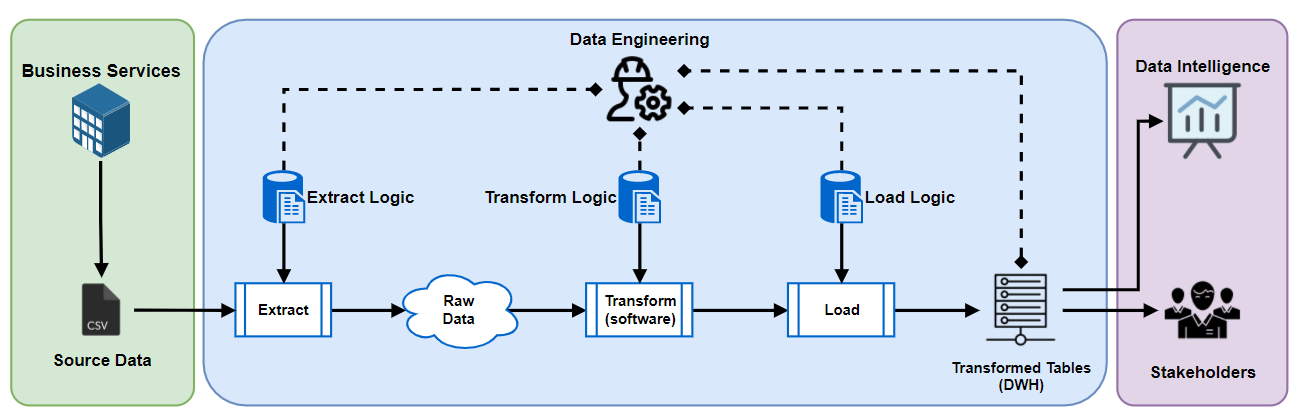
What Can dbt (Data Build Tool) Do for Data Pipeline?
What is DBT (data build tool)?
Data engineers and analysts may construct, manage, and maintain data pipelines in a version-controlled and collaborative environment by utilizing DBT, an open-source data transformation and modeling tool.
DBT is a powerful command line tool for data engineering and data analytics workflows because it lets data teams build scalable data pipelines and data models that are easy to update and test.
In short, dbt (data build tool) turns your data analysts into engineers and allows them to own the entire analytics engineering workflow.
What Can dbt (Data Build Tool) Do for Data Pipeline?
dbt (data build tool) has
two core workflows: building data models and testing data models. It fits nicely into the modern data stack and is cloud agnostic—meaning it works within each of the major cloud ecosystems: Azure, GCP, and AWS.
With dbt, data analysts take ownership of the entire analytics engineering workflow from writing data transformation code all the way through to deployment and documentation—as well as to becoming better able to promote a data-driven culture within the organization. They can:
- Quickly and easily provide clean, transformed data ready for analysis:
dbt enables data analysts to custom-write transformations through SQL SELECT statements. There is no need to write boilerplate code. This makes data transformation accessible for analysts that don’t have extensive experience in other programming languages. - Apply software engineering practices—such as modular code, version control, testing, and continuous integration/continuous deployment (CI/CD)—to analytics code:
- Continuous integration means less time testing and quicker time to development, especially with dbt Cloud. You don’t need to push an entire repository when there are necessary changes to deploy, but rather just the components that change. You can test all the changes that have been made before deploying your code into production. dbt Cloud also has integration with GitHub for automation of your continuous integration pipelines, so you won’t need to manage your own orchestration, which simplifies the process.
- Build reusable and modular code using Jinja.
dbt (data build tool) allows you to establish macros and integrate other functions outside of SQL’s capabilities for advanced use cases. Macros in Jinja are pieces of code that can be used multiple times. Instead of starting at the raw data with every analysis, analysts instead build up reusable data models that can be referenced in subsequent work.
Instead of repeating code to create a hashed surrogate key, create a dynamic macro with Jinja and SQL to consolidate the logic in one spot using dbt. - Maintain data documentation and definitions within dbt as they build and develop lineage graphs:
Data documentation is accessible, easily updated, and allows you to deliver trusted data across the organization. dbt (data build tool) automatically generates documentation around descriptions, models dependencies, model SQL, sources, and tests. dbt creates lineage graphs of the data pipeline, providing transparency and visibility into what the data is describing, how it was produced, as well as how it maps to business logic. - Perform simplified data refreshes within dbt Cloud:
There is no need to host an orchestration tool when using dbt Cloud. It includes a feature that provides full autonomy with scheduling production refreshes at whatever cadence the business wants.
Scheduling is simplified in the dbt Cloud UI. Just give it directions on what time you want a production job to run, and it will take it from there. - Perform automated testing:
dbt (data build tool) comes prebuilt with unique, not null, referential integrity, and accepted value testing. Additionally, you can write your own custom tests using a combination of Jinja and SQL. To apply any test on a given column, you simply reference it under the same YAML file used for documentation for a given table or schema. This makes testing data integrity an almost effortless process.
What is DBT used for? Why use DBT?
In data engineering workflows, DBT is used for tasks like transforming data and making models of it. Some of the most popular ways to use DBT are:
Validating data:
Data engineers may verify the accuracy and security of data as part of the data transformation process thanks to built-in facilities for data validation in DBT. This aids in ensuring the accuracy and consistency of the data in the data pipelines.
Data transformation:
Data engineers can use DBT to transform unstructured raw data into data that has been cleaned, organized, and validated for use in downstream analytics and reporting. It has strong SQL-based transformation capabilities that enable sophisticated data aggregations, filtering, and validation.
Data modeling:
DBT enables data engineers to build data models that incorporate intricate data transformations and calculations, giving data analysts and business users a semantic layer to work with while analyzing data. Since DBT defines data models as code, version control, testing, and documentation are made simple.
Collaboration:
DBT enables an agile method for the building of data pipelines by providing a collaborative environment for data engineers and data analysts to work together. Version control, documentation, and testing are all feasible, which makes it easier for team fellows to collaborate and work together.
How Can I Get Started with dbt (Data Build Tool)?
Prerequisites to Getting Started with dbt (Data Build Tool)
Before learning dbt (data build tool), there are three pre-requisites that we recommend:
- SQL: Since dbt uses SQL as its core language to perform transformations, you must be proficient in using SQL SELECT statements. There are plenty of courses online available if you don’t have this experience, so make sure to find one that gives you the necessary foundation to begin learning dbt.
- Modeling: Like any other data transformation tool, you should have some strategy when it comes to data modeling. This will be critical for re-usability of code, drilling down, and performance optimization. Don’t just adopt the model of your data sources, we recommend transforming data into the language and structure of the business. Modeling will be essential to structure your project and find lasting success.
- Git: If you are interested in learning how to use dbt Core, you will need to be proficient in Git. We recommend finding any course that covers the Git Workflow, Git Branching, and using Git in a team setting. There are lots of great options available online, so explore and find one that you like.
Training To Learn How to Use dbt (Data Build Tool)
There are many ways you can dive in and learn how to use dbt (data build tool). Here are three tips on the best places to start:
- The dbt Labs Free dbt Fundamentals Course: This course is a great starting point for any individual interested in learning the basics on using dbt (data build cloud). This covers many critical concepts like setting up dbt, creating models and tests, generating documentation, deploying your project, and much more.
- The “Getting Started Tutorial” from dbt Labs: Although there is some overlap with concepts from the fundamentals course above, the “getting started tutorial” is a comprehensive hands-on way to learn as you go. There are video series offered for both using dbt Core and dbt Cloud. If you really want to dive in, you can find a sample dataset from online to model out as you go through the videos. This is a great way to learn how to use dbt (data build tool) in a way that will directly reflect how you would build out a project for your organization.
- Join the dbt Slack Community: This is an active community of thousands of members that range from beginner to advanced. There are channels like #learn-on-demand and #advice-dbt-for-beginners that will be very helpful for a beginner to ask questions as they go through the above resources.
What makes DBT different from other tools?
dbt's major features distinguish it from other data transformation tools:
Focus on SQL-based transformations:
dbt employs SQL to define data transformations, making it familiar to SQL-savvy data analysts and engineers. This helps teams integrate dbt into their data transformation workflows by leveraging their SQL skills.
Modularity and reusability:
dbt uses "macros" and "models" for data transformations. Macros are SQL code snippets that can be reused across transformations, while models define transformation logic and data table relationships. This streamlines data pipeline creation and team communication.
Version control and collaboration:
dbt works with version control systems like Git, allowing data teams to cooperate on data transformation projects in an organized manner. This improves team cooperation, versioning, change tracking, and data pipeline change management.
Documentation as code:
dbt makes data pipeline documentation easier by writing data transformations as code. This documentation-as-code approach offers version-controlled documentation, automatic generation, and greater code-documentation alignment.
Testing and validation:
dbt allows data teams to test and validate data transformations. This helps identify data quality issues early in the pipeline, lowering the chance of inaccurate results or insights from defective data.
Community-driven and extensible:
dbt is constantly improving thanks to its active user and contributor community. dbt can also be extended with custom macros, models, and plugins to meet users' data transformation needs.
Data teams seeking a scalable and collaborative data transformation solution like dbt's SQL-based approach, modularity, version control integration, documentation-as-code, testing and validation tools, community-driven nature, and extensibility.